
Get Deeper Observability into dbt Pipelines
Data
General
intermediate
This playbook will show you how to take advantage of Hightouch’s pre-built integrations into dbt so you can get full lineage and better control of your data pipelines.
Made by:Hightouch
6 minutes

Seemingly out of nowhere, dbt Labs sprung to the modern data stack scene in 2016 and no one has been the same since. dbt makes it straightforward to bring software-engineering practices to the world of data engineering…and the movement isn’t slowing down. Increasingly, today’s data workflows are centralized in dbt (and a new class of “analytics engineers” are being minted in the wake). If the warehouse is the hub, dbt has become the mission control layer of the hub that all modern data stacks are gravitating towards.
Due to the increasing ubiquity of dbt, it’s critical that all other data workflows account for dbt and are orchestrated along with it. This is especially true for where that transformed data is going downstream.
Teams rely on Hightouch to drive mission-critical workflows, and when something breaks upstream, it’s essential to view the lineage to quickly understand the root cause and fix the underlying issue.
Hightouch has long-supported leveraging dbt models and dbt Cloud to power and schedule Hightouch syncs. We’ve recently added a dbt observability layer—composed of our GitHub CI checks and dbt Exposure sync features—to give engineers peace of mind that their pipelines between dbt, Hightouch, and operational tools stay resilient.
Let’s say you build Hightouch syncs using models from your dbt repository (for example: using your Salesforce_opportunity model in dbt to drive downstream Hightouch syncs that update opportunities in Salesforce). With our dbt Exposures integration, any active sync which uses a dbt model will automatically create a new dbt exposure back in your Git repository. Now, you can see which Hightouch syncs use what dbt models directly from your dbt docs lineage graph. This gives a helpful birds’-eye-view of how the various entities in your data stack are connected.
Hightouch’s generated dbt exposures also show what dbt model columns a sync is using. The exposure graph also links directly out to all Hightouch resources, keeping you from needing to search in-app manually.
Furthermore, if your team is proposing changes to your dbt models in GitHub, they may not have remembered to check your lineage graph for downstream implications. With dbt CI checks, you have a proactive safety net: each commit in your dbt repo will be checked for downstream breakages, so you have peace of mind that changes to your models won’t break Hightouch syncs.
With this observability layer in place, you now have the visibility needed to better understand lineage between various dependencies in your stack, with proactive guardrails in place to ensure that your pipelines stay resilient.
Make sure you have added a dbt-compatible source to your workspace and have enabled dbt model sync for your connected source. This playbook assumes that you are already familiar with Hightouch’s core concepts and will walk through how to get our dbt observability layer up and running.
Jump to the Extensions tab, click dbt models and choose your connected source.

Toggle dbt exposures sync to “enabled.” Note that Hightouch will require write access to your chosen branch. You can configure the branch for Hightouch to sync Exposures to (e.g., if you want to manually merge generated exposures into your main branch.)

Create a new sync in Hightouch that uses one of your dbt models.

Jump back to your dbt repository and you should soon see Hightouch has made a commit with a generated exposures file. Hightouch will update the generated exposures file whenever there are changes to syncs that use dbt models.

Building your dbt docs should now show your Hightouch exposures on your lineage graph. (Be sure to merge the generated Hightouch dbt Exposures files into your production branch first, if applicable!)
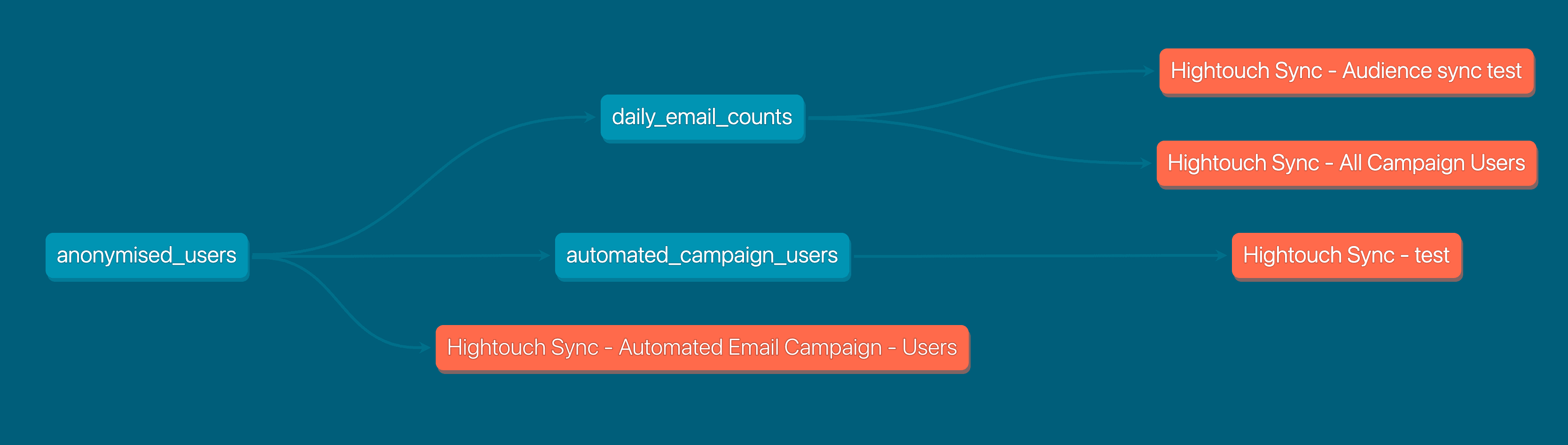
This feature ensures that you don’t make potentially breaking changes in your dbt repo.
Jump to the Extensions tab, click dbt models and choose your connected source.
Toggle on dbt Pull Requests checks and hit save. This gives Hightouch permission to begin checking commits in your dbt Git repo. You may be prompted to re-install the Hightouch GitHub app to allow it to create commit checks.
Now, if you make an edit to one of your dbt models used in a Hightouch sync in a branch in GitHub, you should see Hightouch commit checks running.

If a model that is powering an active downstream Hightouch sync is moved or deleted, the check will fail.
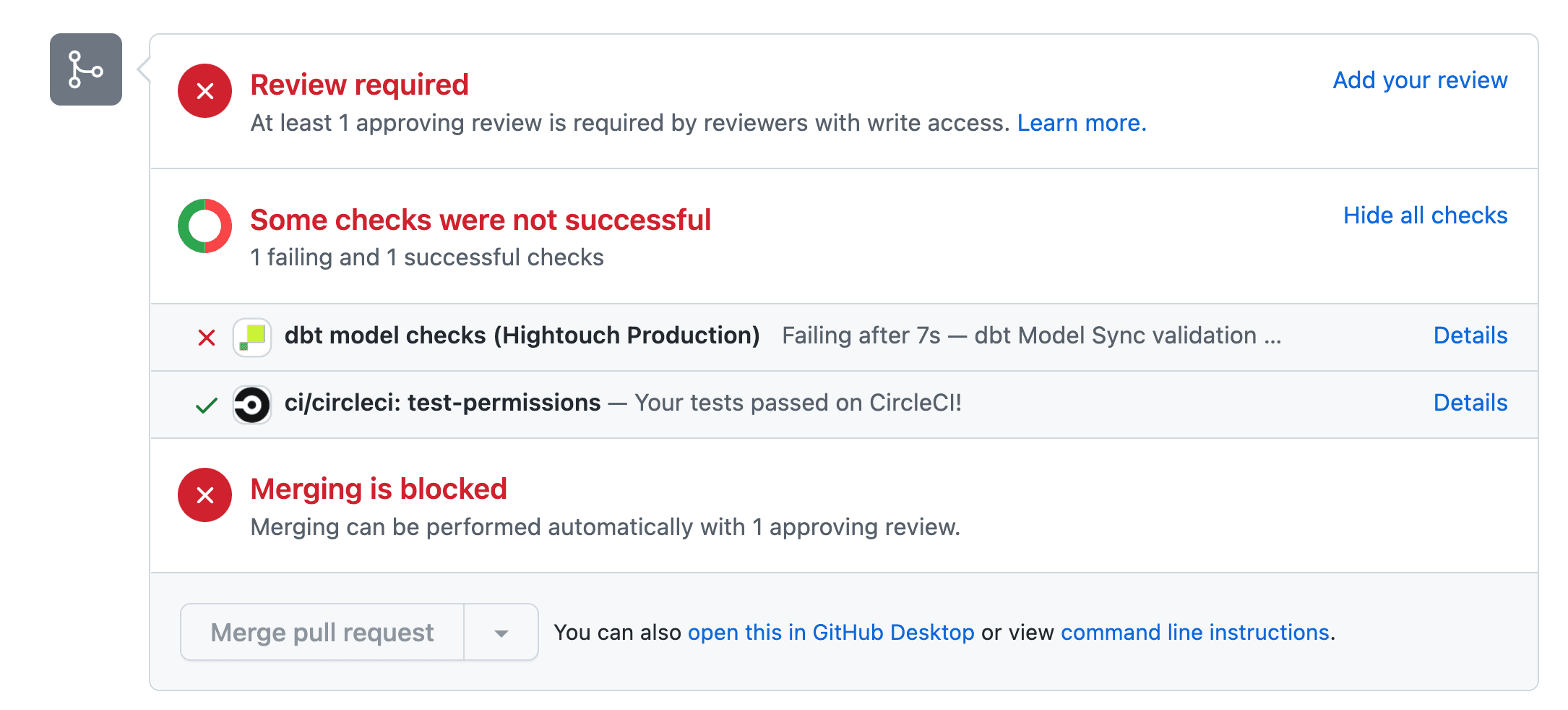
You now have the proactive insights needed to take the appropriate next action (either deactivate the Hightouch sync or revise the changes you’re making to your dbt model to ensure that your pipelines stay resilient).
To take full advantage of these features, try using the dbt-model type for all your Hightouch models. To make it even easier to manage your resources between dbt and Hightouch, you should consider creating a directory in your dbt project specifically for models that will be used in Hightouch syncs. This could be further organized by destination (though one model could certainly be used across multiple destinations, so this may not be how you choose to organize these models), and tags could be assigned to these files or directories to help keep documentation as useful as possible.
Given the wide array of tools in the modern data ecosystem, data teams need assurances that their multi-vendor pipelines stay resilient. That’s why we’ve prioritized building and supporting industry-leading integrations into dbt Cloud. When activating their dbt models with Hightouch, data teams can be confident that they have the visibility and guardrails they need to control how data flows through their stack.
Want to learn more? Check out our other playbooks or book a demo with our team of experts today!